|
|
vlrMemos |
vlrMemos, Mémos Audio, Qualité de la Voix et Son Positionnel 3D
Application Audio pour Ordinateurs, Tablettes, Smartphones et Objets Connectés
Compatible avec les Signaux Physiologiques et les Données de Variabilité
Résumé
vlrMemos est une application pour enregistrer des mémos vocaux ou audio et pour mesurer la qualité de la voix.
L'application pourra calculer et afficher en temps réel des paramètres acoustiques comme le LTAS (Spectre Moyen à Long Terme, Long-Term Average Spectrum en Anglais) et le HPR (Rapport de Puissance Hautes Fréquences, High-Frequency Power Ratio en Anglais).
Lors de la lecture des enregistrements, l'application pourra ajouter le calcul et l'affichage d'autres paramètres comme le Jitter, le Shimmer ou le HNR (Rapport Harmonique sur Bruit, Harmonic to Noise Ratio en Anglais).
Les paramètres avancés tels que le CPP (Pic de Proéminence Cepstral ou Cepstral Peak Prominence en Anglais) et le CPPS (Pic de Proéminence Cepstral Lissé ou Smoothed Cepstral Peak Prominence en Anglais), qui sont des mesures fiables de la dysphonie, seront également calculés et affichés. Enfin, les paramètres spectraux mesurant le ralentissement du spectre, la perte de complexité du signal ou la similarité entre plusieurs canaux seront calculés et affichés.
Durant les restitutions sonores, avant la décompression, des filtres FIR (Filtre à Réponse Impulsionnelle Finie, Finite Impulse Response en Anglais) générés à partir d'audiogrammes normalisés et non normalisés, seront appliqués aux canaux dans le domaine de Fourier (convolutions rapides), pour des sorties audio hautement optimisées et sur mesure.
L'application sera disponible pour les ordinateurs, les tablettes, les smartphones, les montres et les objets connectés.
Elle pourra utiliser un codec audio (méthode de compression et de décompression audio) très rapide, de grande qualité, basé sur FFT (Transformation de Fourier Rapide, Fast Fourier Transform en Anglais) et pouvant être accéléré avec le support GPU (support du processeur graphique, Graphics Processing Unit en Anglais), pour une consommation très faible de batterie.
Ce codec est quasi sans perte en énergie: l'énergie d'une trame non compressée est presque aussi égale à celle de la trame compressée.
Ce codec peut fournir l'audio en 3D. Durant les restitutions sonores, avant la décompression, des filtres HRTF (Fonction de Transfert Relative à la Tête, Head-Related Transfer Function en Anglais) génériques ou personnalisés sont appliqués aux canaux dans le domaine de Fourier (opérations très rapides), pour un son positionnel 3D de grande qualité.
L'application va être compatible avec les sons du corps, les signaux physiologiques et les données de variabilité.
En utilisant cette application, on pourra:
- Détecter des anomales dans la voix.
- Suivre l'efficacité d'un traitement de la voix.
- Suivre les progrès réalisés lors d'un entraînement de la voix ou lors d'une rééducation vocale.
- Enregistrer et analyser les sons de battements de coeur et les sons pulmonaires.
- Enregistrer et analyser les signaux physiologiques.
- En option, effectuer la sonification des signaux physiologiques et des données de variabilité.
- En option, envoyer les valeurs moyennes de certains paramètres sous forme de codes d'intensité et / ou de couleur (notifications lumineuses) à des ampoules connectées ou à des ponts d'ampoules connectées.
- En option, afficher les courbes de valeurs pour les paramètres acoustiques sélectionnés.
- En option, calculer et afficher la variabilité de la fréquence cardiaque (VFC).
Description
Plusieurs paramètres acoustiques existent pour mesurer la qualité de la voix.
On peut citer:
- Le LTAS: Spectre Moyenné à Long Terme, ou Long-Term Average Spectrum en Anglais.
Permet de mesurer la qualité de la voix. Il fournit une mesure objective de l'évaluation de cette qualité qui dépend habituellement de la perception auditive.
Il fournit une analyse spectrale moyennée de longue durée.
- Le HPR: Rapport de Puissance Hautes Fréquences ou High-Frequency Power Ratio en Anglais.
Permet la détection de voix soufflées. Il compare la proportion de l'énergie acoustique dans les hautes fréquences à la proportion de l'énergie dans les basses fréquences.
- Le Jitter:
Permet de mesurer les irrégularités dans les durées. Il mesure les perturbations à court terme de la fréquence fondamentale du signal sonore.
- Le Shimmer:
Permet de mesurer les irrégularités dans les amplitudes. Il mesure les perturbations à court terme de l'amplitude du signal sonore.
- Le HNR: Rapport Harmonique sur Bruit ou Harmonic to Noise Ratio en Anglais.
Permet de mesurer l'harmonicité du signal. Il mesure le niveau de bruit dans le signal sonore.
Le CPP: Pic de Proéminence Cepstral ou Cepstral Peak Prominence en Anglais.
Le CPPS: Pic de Proéminence Cepstral Lissé ou Smoothed Cepstral Peak Prominence en Anglais.
Permet d'estimer la sévérité de la dysphonie. Ces paramètres sont de bons prédicteurs et sont des mesures fiables de la dysphonie.
- L'Entropie Spectrale (Shannon et Rényi):
Permet de mesurer le degré de complexité d'un signal. Un signal avec bruit va tendre vers 1 tandis qu'un ton pur va tendre vers 0.
- Le Point de Rolloff Spectral:
Permet de déterminer la fréquence en dessous de laquelle il y a 95% de la distribution des magnitudes.
- Le Centroïde Spectral:
Permet de déterminer le centre de masse du spectre.
Le MCCC: Coefficient de Corrélation Croisé Multicanal ou Multichannel Cross Correlation Coefficient en Anglais.
Permet de mesurer le degré de similarité entre plusieurs canaux.
En option, les paramètres ci-dessous seront calculés et affichés:
- Le COG: Centre de Gravité.
Permet de mesurer le timbre musical ou la brillance du signal sonore.
- L' Ecart Absolu Moyen:
Permet de mesurer la dispersion des magnitudes ou des fréquences fondamentales autour de la moyenne.
- L'Ecart Type:
Permet de mesurer la dispersion des magnitudes ou des fréquences fondamentales autour de la moyenne.
- Le Skewness: Coefficient de Dissymétrie.
Permet de mesurer l'asymétrie de la distribution des magnitudes ou des fréquences fondamentales.
- Le Kurtosis: Coefficient d'Aplatissement.
Permet de mesurer l'aplatissement de la distribution des magnitudes ou des fréquences fondamentales.
vlrMemos est une application qui va permettre d'enregistrer des mémos vocaux ou audio et d'afficher ces paramètres.
Le LTAS et le HPR seront affichés en temps réel et lors des lectures des enregistrements vocaux.
Le Jitter, le Shimmer, le HNR, le CPP, le CPPS et d'autres paramètres seront affichés lors des lectures.
Les valeurs affichées en temps réel seront calculées avec les échantillons non compressés.
Les valeurs affichées lors des lectures seront calculées avec les échantillons compressés ou non compressés selon l'option de sauvegarde.
La sauvegarde des données en mémoire ou sur disque pourra être au format WAVE classique (compressé ou non compressé). On proposera par défaut le codec VLC HQ 48 et le format WAVE compressé.
Nous allons proposer en option le format W64 (Sony Picture digital Wave 64 en Anglais), avec des échantillons compressés ou non compressés. Ce format supporte des fichiers de plus de 4 Go.
Codec VLC HQ 48
Codec audio très rapide et de grande qualité, utilisant FFT.
Les enregistrements seront au format WAVE compressé. Ils contiendront directement les valeurs codées des fréquences (positions), magnitudes et phases.
Le codec utilisant le domaine des fréquences et FFT, pendant les lectures, il n'y a plus besoin de refaire FFT pour recalculer les paramètres acoustiques si on utilise le format WAVE compressé. Avec le format WAVE non compressé, il faut refaire FFT.
Le codec utilisant FFT, il peut être accéléré grâce à la programmation GPU.
En outre, il utilise les plus grands points et les bandes les plus énergétiques. Les bandes seront encodées indépendamment les unes des autres, donc on pourra les encoder en parallèle et utiliser également l'accélération GPU.
La programmation GPU permettra d'avoir de très faibles consommations de batterie.
On trouvera plus d'informations sur ce codec aux adresses suivantes:
- Algorithmes
- VLB
Il faut noter que la version actuelle du codec est quasi sans perte en énergie: l'énergie d'une trame non compressée est presque aussi égale à celle de la trame compressée.
Il n'y pas de notion de psycho-acoustique, tous les points peuvent être pris en compte.
Il n'y pas de notion de trames similaires, notion utile pour les communications.
Il faut noter aussi que l'utilisation de la compression permet d'avoir besoin de moins de mémoire, de limiter la taille des données à transférer et d'économiser l'espace de stockage.
Sans compression, avec un canal, 16 bits et 48 kHz de fréquence d'échantillonnage, une seconde de voix occupe 0,768 Mbits (méga bits), 30 secondes occupent 23,040 MBits, une minute occupe 46,080 Mbits et 5 minutes occupent 230,400 Mbits.
Avec compression par le codec VLC HQ 48 à 64000 bps, une seconde de voix occupe 0,064 Mbits (méga bits), 30 secondes occupent 1,92 MBits, une minute occupe 3,84 Mbits et 5 minutes occupent 19,2 Mbits.
Ce codec va supporter le multicanal (en option).
Codec VLC HQ 16
Pour prendre en compte les sons du corps (très basses fréquences) et les durées d'enregistrement très longues, une fréquence d'échantillonnage moins élevée (16 kHZ et moins au lieu de 48 kHz) sera utilisée.
Le codec VLC HQ 16 supportera en outre le multicanal (en option), pour la transmission des données du genre ECG (ElectroCardioGramme).
Des données telles que l'EEG (ElectroEncéphaloGramme) ou l'EMG (ElectroMyoGramme) seront supportées. Les données des formes d'ondes de la pression sanguine artérielle (ABP ou Arterial Blood Pressure en Anglais) et les données des formes d'ondes de la pléthysmographie (à partir de l'oxymétrie pulsée appelée aussi l'oxymétrie de pouls) vont être également supportées. Enfin, les données des formes d'ondes de la glycémie vont être supportées.
Le multicanal sera compatible avec l'Interface Audio USB 2.0.
Si utile, on utilisera une compression additionnelle sans perte.
Le nombre de trames par seconde est de 31,25 environ pour l'audio. Il sera aux alentours de 0,5 à 2,0 trames par seconde pour les signaux physiologiques.
On trouvera plus d'informations sur la prise en compte des données de l'ECG et l'utilisation de ce codec pour la télésurveillance médicale à l'adresse suivante:
- Télésurveillance Médicale
Codecs VLC 3D 48 et VLC HQ 3D 48
Ces codecs vont être compatibles avec l'audio positionnel 3D.
Les filtres HRTF (Fonction de Transfert Relative à la Tête, Head-Related Transfer Function en Anglais), personnalisables, seront appliqués aux sorties en mono, stéréo ou multicanal.
Les filtres HRTF personnalisés sont utiles non seulement pour les effets audio 3D, mais aussi comme aides auditives pour les malentendants.
Il faut noter une propriété intéressante qu'on ne retrouve dans aucun autre codec audio non FFT: les trames compressées étant directement dans le domaine de Fourier, il n'est pas nécessaire d'effectuer de transformation FFT afin d'appliquer les filtres HRTF.
- Plus d'Informations
Filtres FIR Personnalisés
Possibilité de charger des filtres FIR (Filtre à Réponse Impulsionnelle Finie, Finite Impulse Response en Anglais) personnalisés pour tous les codecs et toutes les fréquences d'échantillonnage.
Ceci est utile pour des sorties audio personnalisées et des corrections auditives. Les filtres sont générés à partir de fichiers texte contenant la sensibilité relative de chaque oreille à différentes fréquences (comme les données d'audiogramme).
La longueur des filtres FIR pourra aller jusqu'à 1536 échantillons pour un seul canal avec une fréquence d'échantillonnage de 48 kHz. Les filtres FIR sont appliqués dans le domaine de Fourier (convolutions rapides).
Variabilité de la Fréquence Cardiaque (VFC)
- En option, nous allons calculer et afficher la variabilité de la fréquence cardiaque (VFC) à partir des sons de battements de coeur, des signaux ECG ou des données de variabilité. Plus d'informations sur la VFC à l'adresse suivante:
- Variabilité de la Fréquence Cardiaque
Données de Variabilité
On s'intéresse à des données comme les variations du rythme cardiaque en fonction du temps ou les variations de la pression artérielle systolique en fonction du temps. Ces données permettent de calculer la variabilité de la fréquence cardiaque ou de la pression artérielle. Il y a typiquement 60 à 100 échantillons par seconde, donc 5 minutes de données occupent un tampon de 300 à 500 échantillons. On émettra des tampons contenant 1024 échantillons. D'autres types de données peuvent être considérés.
Les données en entrée seront sous forme de lignes au format texte CSV (temps, donnée).
Si il y a N canaux, les lignes seront sous la forme:
- (temp1,donnée1,temps2, donnée2,...,tempsN,donnéeN).
La fréquence d'échantillonnage (minimum) après interpolation sera:
- fréquence d'échantillonnage = (nombre total d'échantillons / temps total).
Le nombre (minimum) de trames par seconde sera:
- trames par seconde = (fréquence d'échantillonnage / 1024).
Des fréquences d'échantillonnage très basses ou très élevées ne sont pas des problèmes avec nos codecs.
Les enregistrements seront des fichiers WAVE compressés ou non compressés selon l’option de sauvegarde. Au lieu d'afficher le LTAS ou le HPR, nous allons afficher l'énergie spectrale pour les basses fréquences (LF), l'énergie spectrale pour les hautes fréquences (HF) ainsi que le rapport LF/HF.
Sonification
La sonification concerne les signaux physiologiques et les données de variabilité. Durant les enregistrements ou les lectures, par défaut, il n'y a pas de son pour ces signaux ou ces données, mais des affichages des valeurs des paramètres pour un canal ou pour la moyenne des canaux.
En option, nous allons générer un son par canal (le multicanal sera possible), à l'aide d'un algorithme de sonification de bonne qualité. Nous allons utiliser la sonification par mapping spectral (Spectral Mapping Sonification en Anglais).
La sonification par mapping spectral permet de surveiller toutes les fréquences ou une bande précise de fréquences.
Des études récentes ont montré, par exemple, qu'on pouvait entendre la différence entre un rythme cardiaque normal et un rythme cardiaque anormal grâce à la sonification des signaux de l'ECG.
Plus d'informations sur la sonification des données avec vlrMemos à l'adresse suivante:
- Sonification des Données avec vlrMemos
Envoyer et Partager
Il n'est pas prévu dans l'immédiat d'avoir des fonctions d'envoi et de partage des fichiers créés par vlrMemos. On pourra se servir des applications de messagerie permettant d'envoyer des fichiers (WhatsApp, Skype, ...).
On pourra lire les fichiers WAVE (non compressés ou compressés avec vlrMemos) dans les répertoires accessibles en lecture.
En utilisant vlrMemos en lecture, on pourra utiliser des filtres FIR et HTRF personnalisés. En utilisant les codecs VLC, on pourra utiliser plus efficacement ces filtres, car il n'y aura pas besoin de se placer dans le domaine de Fourier.
Financement Participatif
Nous allons considérer les systèmes d'exploitation suivants:
- Windows.
- Android et Android Wear.
- iOS (iPhone et iPad) et watchOS (Apple Watch).
- Windows Phone.
En option, tous les systèmes supportés par PJSIP pourront être considérés.
La programmation GPU sera faite via les Compute Shaders (disponibles à partir d'OpenGL 4.3 et d'OpenGL ES 3.1).
En option, il y aura le support du SDK MARE (Multicore Asynchronous Runtime Environment en Anglais), dédié au système d'exploitation Android et aux SoCs Qualcomm Snapdragon (GPU Adreno), et du SDK Metal, dédié au système d'exploitation iOS.
Plus d'informations sur le support GPU avec les appareils portables aux adresses suivantes:
- Appareils Portables
- SDK MARE
- SDK Metal
Pour les contreparties, voir sur le site web du financement participatif.
Contrairement à vlrPhone qui est complètement Open Source, vlrMemos va comporter quelques parties propriétaires, principalement l'interface graphique.
PJSIP, tous les codecs VLC et VLR ainsi que d'autres librairies sont Open Source. Les librairies Open Source seront liées statiquement ou dynamiquement aux modules propriétaires. Les codes sources de toutes les librairies Open Source seront publiques.
Utilité
Les paramètres acoustiques calculés et affichés permettront de mesurer la qualité de la voix en vue de:
- détecter des anomalies dans la voix;
- suivre l'efficacité d'un traitement de la voix;
- suivre les progrès réalisés lors d'un entraînement de la voix ou lors d'une rééducation vocale.
On pourra aussi les utiliser à des fins de classification et de recherche.
Nous signalerons en rouge les données en dessous des seuils considérés comme pouvant être pathologiques.
En option, l'application va aussi afficher les courbes de valeurs pour les paramètres acoustiques sélectionnés.
L'application va être compatible avec les sons du corps différents de la voix, dans des situations réelles.
On pourra enregistrer et analyser les sons de battements de coeur et des sons pulmonaires.
L'application sera compatible avec de longs enregistrements.
Nos codecs sont basés sur FFT et stockent directement les valeurs des fréquences, des magnitudes et des phases. En plus de la compression des données, on peut avoir la densité spectrale des signaux lors des lectures, sans refaire de FFT.
La densité spectrale indique la puissance de chaque composante fréquentielle du signal. La densité spectrale peut être utilisée pour analyser directement une variété de signaux physiologiques.
Une modification de la voix est appelée dysphonie, et une voix réduite au chuchotement est appelée aphonie.
Les maladies entraînant des troubles de la voix peuvent être soignées ou retardées plus efficacement si elles sont détectées très tôt.
On peut citer par exemple:
- La laryngite aiguë.
- Le malmenage ou surmenage vocal et les dysphonies dysfonctionnelles.
- Les lésions bénignes des cordes vocales.
- La papillomatose laryngée.
- Les laryngites chroniques.
- La paralysie laryngée.
- Les dysphonies spasmodiques.
- Le cancer des cordes vocales (cancer de la gorge).
- La dysarthrie qui est une faiblesse ou une paralysie des cordes vocales causée par des dommages aux nerfs et/ou au cerveau, par exemple en cas de sclérose en plaques, d'accident vasculaire cérébral ou de maladie de Parkinson.
- L'aphasie qui est due à une perte de la parole ou à des troubles du langage parlé et/ou écrit, par exemple en cas de maladie d'Alzheimer.
Pour certaines professions (comme les conférenciers, les coaches, les enseignants, les animateurs et les chanteurs par exemple), la qualité de la voix est fondamentale.
Pour les fumeurs, la détection d'une anomalie persistante de la voix peut permettre la détection précoce d'une maladie grave comme le cancer du poumon.
L'intérêt de la variabilité de la fréquence cardiaque (VFC) a été démontré dans l'analyse de la récupération des sportifs. La VFC est un excellent indicateur de niveau de santé général et un facteur prédictif de l'hypertension. Un diminution de l'énergie spectrale signale un risque d'évènements cardiaques.
La mesure de la dysphonie permet la détection et le suivi efficace de la maladie de Parkinson.
La maladie d'Alzheimer est caractérisée par:
- Le ralentissement de l'EEG (l'ElectroEncéphalogramme), c'est-à-dire une élévation de la puissance des magnitudes dans les basses fréquences.
- La perte de complexité des signaux de l'EEG.
- La perte de synchronie des signaux de l'EEG.
A partir des signaux issus de l'EEG, les paramètre spectraux ainsi que le coefficient de corrélation croisé multicanal permettent de quantifier ces anomalies.
Des mesures de synchronie plus complexes existent, comme:
- La syncronie de phase.
- Le module Carré de la Cohérence (Magnitude Squared Coherence ou MSC en Anglais).
- La causalité de Granger et les mesures dérivées, notamment la Fonction de Transfert Directe (Direct Transfer Function ou DTF en Anglais). Ces mesures utilisent des zones précises du domaine des fréquences. On pourra utiliser directement les enregistrements dans le domaine des fréquences, surtout dans un contexte de télésurveillance.
Pour terminer, on peut signaler que l'analyse spectrale de puissance des signaux de l'EEG est l'outil le plus utilisé dans la recherche sur le sommeil.
Interfaces de l'Application
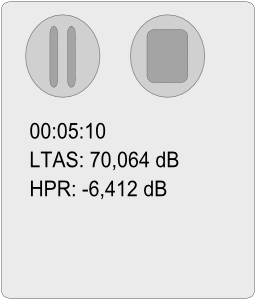
Exemples de Résultats
Version = V7 (quasi sans perte en énergie).
LTAS = Spectre Moyenné à Long Terme (Long-Term Average Spectrum en Anglais).
HPR = Rapport de Puissance Hautes Fréquences (High-Frequency Power Ratio en Anglais), avec:
(1)
Plage basses fréquences: 0 - 500 Hz,
Plage hautes fréquences: 500 - 4000 Hz.
(2)
Plage basses fréquences: 0 - 6000 Hz,
Plage hautes fréquences: 6000 - 20000 Hz.
Calculs avec le programme gratuit PRAAT.
Pour le CPPS (Pic de Proéminence Cepstral Lissé ou Smoothed Cepstral Peak Prominence en Anglais), les valeurs par défaut de PRAAT sont utilisées avec la fenêtre moyenne de la quéfrence égale à 0,032 seconde.
Sujets
Mémos Vocaux.
Mémos Audio, Mémos Sonores.
Mesure de la Qualité de la Voix.
Entraînement de la Voix.
Paramètres Acoustiques.
Spectre Moyenné à Long Terme (Long-Term Average Spectrum ou LTAS en Anglais).
Rapport de Puissance Hautes Fréquences (High-Frequency Power Ratio ou HPR en Anglais).
Jitter.
Shimmer.
Rapport Harmonique sur Bruit (Harmonic to Noise Ratio ou HNR en Anglais).
Pic de Proéminence Cepstral (Cepstral Peak Prominence ou CPP en Anglais).
Pic de Proéminence Cepstral Lissé (Smoothed Cepstral Peak Prominence ou CPPS en Anglais).
Entropie Spectrale.
Point de Rolloff Spectral.
Centroïde Spectral.
Coefficient de Corrélation Croisé Multicanal (Multichannel Cross Correlation Coefficient ou MCCC en Anglais).
Centre de Gravité (Center of Gravity ou COG en Anglais).
Ecart Absolu Moyen, Ecart Type.
Skewness, Kurtosis.
Variabilité de la Fréquence Cardiaque (VFC).
Sons Cardiaques ou Sons de Battements de Coeur.
Sons Pulmonaires ou Sons Respiratoires.
Auto-Quantification (Quantified Self ou Self Training en Anglais).
Sonification par Mapping Spectral (Spectral Mapping Sonification en Anglais).
Audio 3D, Audio Positionnel 3D.
HRTF (Fonction de Transfert Relative à la Tête, Head-Related Transfer Function en Anglais).
Processeur Graphique (GPU, Graphics Processing Unit en Anglais).
vlrMemos est une application pour enregistrer des mémos vocaux ou audio et pour mesurer la qualité de la voix.
L'application pourra calculer et afficher en temps réel des paramètres acoustiques comme le LTAS (Spectre Moyen à Long Terme, Long-Term Average Spectrum en Anglais) et le HPR (Rapport de Puissance Hautes Fréquences, High-Frequency Power Ratio en Anglais).
Lors de la lecture des enregistrements, l'application pourra ajouter le calcul et l'affichage d'autres paramètres comme le Jitter, le Shimmer ou le HNR (Rapport Harmonique sur Bruit, Harmonic to Noise Ratio en Anglais).
Les paramètres avancés tels que le CPP (Pic de Proéminence Cepstral ou Cepstral Peak Prominence en Anglais) et le CPPS (Pic de Proéminence Cepstral Lissé ou Smoothed Cepstral Peak Prominence en Anglais), qui sont des mesures fiables de la dysphonie, seront également calculés et affichés. Enfin, les paramètres spectraux mesurant le ralentissement du spectre, la perte de complexité du signal ou la similarité entre plusieurs canaux seront calculés et affichés.
Durant les restitutions sonores, avant la décompression, des filtres FIR (Filtre à Réponse Impulsionnelle Finie, Finite Impulse Response en Anglais) générés à partir d'audiogrammes normalisés et non normalisés, seront appliqués aux canaux dans le domaine de Fourier (convolutions rapides), pour des sorties audio hautement optimisées et sur mesure.
L'application sera disponible pour les ordinateurs, les tablettes, les smartphones, les montres et les objets connectés.
Elle pourra utiliser un codec audio (méthode de compression et de décompression audio) très rapide, de grande qualité, basé sur FFT (Transformation de Fourier Rapide, Fast Fourier Transform en Anglais) et pouvant être accéléré avec le support GPU (support du processeur graphique, Graphics Processing Unit en Anglais), pour une consommation très faible de batterie.
Ce codec est quasi sans perte en énergie: l'énergie d'une trame non compressée est presque aussi égale à celle de la trame compressée.
Ce codec peut fournir l'audio en 3D. Durant les restitutions sonores, avant la décompression, des filtres HRTF (Fonction de Transfert Relative à la Tête, Head-Related Transfer Function en Anglais) génériques ou personnalisés sont appliqués aux canaux dans le domaine de Fourier (opérations très rapides), pour un son positionnel 3D de grande qualité.
L'application va être compatible avec les sons du corps, les signaux physiologiques et les données de variabilité.
En utilisant cette application, on pourra:
- Détecter des anomales dans la voix.
- Suivre l'efficacité d'un traitement de la voix.
- Suivre les progrès réalisés lors d'un entraînement de la voix ou lors d'une rééducation vocale.
- Enregistrer et analyser les sons de battements de coeur et les sons pulmonaires.
- Enregistrer et analyser les signaux physiologiques.
- En option, effectuer la sonification des signaux physiologiques et des données de variabilité.
- En option, envoyer les valeurs moyennes de certains paramètres sous forme de codes d'intensité et / ou de couleur (notifications lumineuses) à des ampoules connectées ou à des ponts d'ampoules connectées.
- En option, afficher les courbes de valeurs pour les paramètres acoustiques sélectionnés.
- En option, calculer et afficher la variabilité de la fréquence cardiaque (VFC).
Description
Plusieurs paramètres acoustiques existent pour mesurer la qualité de la voix.
On peut citer:
- Le LTAS: Spectre Moyenné à Long Terme, ou Long-Term Average Spectrum en Anglais.
Permet de mesurer la qualité de la voix. Il fournit une mesure objective de l'évaluation de cette qualité qui dépend habituellement de la perception auditive.
Il fournit une analyse spectrale moyennée de longue durée.
- Le HPR: Rapport de Puissance Hautes Fréquences ou High-Frequency Power Ratio en Anglais.
Permet la détection de voix soufflées. Il compare la proportion de l'énergie acoustique dans les hautes fréquences à la proportion de l'énergie dans les basses fréquences.
- Le Jitter:
Permet de mesurer les irrégularités dans les durées. Il mesure les perturbations à court terme de la fréquence fondamentale du signal sonore.
- Le Shimmer:
Permet de mesurer les irrégularités dans les amplitudes. Il mesure les perturbations à court terme de l'amplitude du signal sonore.
- Le HNR: Rapport Harmonique sur Bruit ou Harmonic to Noise Ratio en Anglais.
Permet de mesurer l'harmonicité du signal. Il mesure le niveau de bruit dans le signal sonore.
Le CPP: Pic de Proéminence Cepstral ou Cepstral Peak Prominence en Anglais.
Le CPPS: Pic de Proéminence Cepstral Lissé ou Smoothed Cepstral Peak Prominence en Anglais.
Permet d'estimer la sévérité de la dysphonie. Ces paramètres sont de bons prédicteurs et sont des mesures fiables de la dysphonie.
- L'Entropie Spectrale (Shannon et Rényi):
Permet de mesurer le degré de complexité d'un signal. Un signal avec bruit va tendre vers 1 tandis qu'un ton pur va tendre vers 0.
- Le Point de Rolloff Spectral:
Permet de déterminer la fréquence en dessous de laquelle il y a 95% de la distribution des magnitudes.
- Le Centroïde Spectral:
Permet de déterminer le centre de masse du spectre.
Le MCCC: Coefficient de Corrélation Croisé Multicanal ou Multichannel Cross Correlation Coefficient en Anglais.
Permet de mesurer le degré de similarité entre plusieurs canaux.
En option, les paramètres ci-dessous seront calculés et affichés:
- Le COG: Centre de Gravité.
Permet de mesurer le timbre musical ou la brillance du signal sonore.
- L' Ecart Absolu Moyen:
Permet de mesurer la dispersion des magnitudes ou des fréquences fondamentales autour de la moyenne.
- L'Ecart Type:
Permet de mesurer la dispersion des magnitudes ou des fréquences fondamentales autour de la moyenne.
- Le Skewness: Coefficient de Dissymétrie.
Permet de mesurer l'asymétrie de la distribution des magnitudes ou des fréquences fondamentales.
- Le Kurtosis: Coefficient d'Aplatissement.
Permet de mesurer l'aplatissement de la distribution des magnitudes ou des fréquences fondamentales.
vlrMemos est une application qui va permettre d'enregistrer des mémos vocaux ou audio et d'afficher ces paramètres.
Le LTAS et le HPR seront affichés en temps réel et lors des lectures des enregistrements vocaux.
Le Jitter, le Shimmer, le HNR, le CPP, le CPPS et d'autres paramètres seront affichés lors des lectures.
Les valeurs affichées en temps réel seront calculées avec les échantillons non compressés.
Les valeurs affichées lors des lectures seront calculées avec les échantillons compressés ou non compressés selon l'option de sauvegarde.
La sauvegarde des données en mémoire ou sur disque pourra être au format WAVE classique (compressé ou non compressé). On proposera par défaut le codec VLC HQ 48 et le format WAVE compressé.
Nous allons proposer en option le format W64 (Sony Picture digital Wave 64 en Anglais), avec des échantillons compressés ou non compressés. Ce format supporte des fichiers de plus de 4 Go.
Codec VLC HQ 48
Codec audio très rapide et de grande qualité, utilisant FFT.
Les enregistrements seront au format WAVE compressé. Ils contiendront directement les valeurs codées des fréquences (positions), magnitudes et phases.
Le codec utilisant le domaine des fréquences et FFT, pendant les lectures, il n'y a plus besoin de refaire FFT pour recalculer les paramètres acoustiques si on utilise le format WAVE compressé. Avec le format WAVE non compressé, il faut refaire FFT.
Le codec utilisant FFT, il peut être accéléré grâce à la programmation GPU.
En outre, il utilise les plus grands points et les bandes les plus énergétiques. Les bandes seront encodées indépendamment les unes des autres, donc on pourra les encoder en parallèle et utiliser également l'accélération GPU.
La programmation GPU permettra d'avoir de très faibles consommations de batterie.
On trouvera plus d'informations sur ce codec aux adresses suivantes:
- Algorithmes
- VLB
Il faut noter que la version actuelle du codec est quasi sans perte en énergie: l'énergie d'une trame non compressée est presque aussi égale à celle de la trame compressée.
Il n'y pas de notion de psycho-acoustique, tous les points peuvent être pris en compte.
Il n'y pas de notion de trames similaires, notion utile pour les communications.
Il faut noter aussi que l'utilisation de la compression permet d'avoir besoin de moins de mémoire, de limiter la taille des données à transférer et d'économiser l'espace de stockage.
Sans compression, avec un canal, 16 bits et 48 kHz de fréquence d'échantillonnage, une seconde de voix occupe 0,768 Mbits (méga bits), 30 secondes occupent 23,040 MBits, une minute occupe 46,080 Mbits et 5 minutes occupent 230,400 Mbits.
Avec compression par le codec VLC HQ 48 à 64000 bps, une seconde de voix occupe 0,064 Mbits (méga bits), 30 secondes occupent 1,92 MBits, une minute occupe 3,84 Mbits et 5 minutes occupent 19,2 Mbits.
Ce codec va supporter le multicanal (en option).
Codec VLC HQ 16
Pour prendre en compte les sons du corps (très basses fréquences) et les durées d'enregistrement très longues, une fréquence d'échantillonnage moins élevée (16 kHZ et moins au lieu de 48 kHz) sera utilisée.
Le codec VLC HQ 16 supportera en outre le multicanal (en option), pour la transmission des données du genre ECG (ElectroCardioGramme).
Des données telles que l'EEG (ElectroEncéphaloGramme) ou l'EMG (ElectroMyoGramme) seront supportées. Les données des formes d'ondes de la pression sanguine artérielle (ABP ou Arterial Blood Pressure en Anglais) et les données des formes d'ondes de la pléthysmographie (à partir de l'oxymétrie pulsée appelée aussi l'oxymétrie de pouls) vont être également supportées. Enfin, les données des formes d'ondes de la glycémie vont être supportées.
Le multicanal sera compatible avec l'Interface Audio USB 2.0.
Si utile, on utilisera une compression additionnelle sans perte.
Le nombre de trames par seconde est de 31,25 environ pour l'audio. Il sera aux alentours de 0,5 à 2,0 trames par seconde pour les signaux physiologiques.
On trouvera plus d'informations sur la prise en compte des données de l'ECG et l'utilisation de ce codec pour la télésurveillance médicale à l'adresse suivante:
- Télésurveillance Médicale
Codecs VLC 3D 48 et VLC HQ 3D 48
Ces codecs vont être compatibles avec l'audio positionnel 3D.
Les filtres HRTF (Fonction de Transfert Relative à la Tête, Head-Related Transfer Function en Anglais), personnalisables, seront appliqués aux sorties en mono, stéréo ou multicanal.
Les filtres HRTF personnalisés sont utiles non seulement pour les effets audio 3D, mais aussi comme aides auditives pour les malentendants.
Il faut noter une propriété intéressante qu'on ne retrouve dans aucun autre codec audio non FFT: les trames compressées étant directement dans le domaine de Fourier, il n'est pas nécessaire d'effectuer de transformation FFT afin d'appliquer les filtres HRTF.
- Plus d'Informations
Filtres FIR Personnalisés
Possibilité de charger des filtres FIR (Filtre à Réponse Impulsionnelle Finie, Finite Impulse Response en Anglais) personnalisés pour tous les codecs et toutes les fréquences d'échantillonnage.
Ceci est utile pour des sorties audio personnalisées et des corrections auditives. Les filtres sont générés à partir de fichiers texte contenant la sensibilité relative de chaque oreille à différentes fréquences (comme les données d'audiogramme).
La longueur des filtres FIR pourra aller jusqu'à 1536 échantillons pour un seul canal avec une fréquence d'échantillonnage de 48 kHz. Les filtres FIR sont appliqués dans le domaine de Fourier (convolutions rapides).
Variabilité de la Fréquence Cardiaque (VFC)
- En option, nous allons calculer et afficher la variabilité de la fréquence cardiaque (VFC) à partir des sons de battements de coeur, des signaux ECG ou des données de variabilité. Plus d'informations sur la VFC à l'adresse suivante:
- Variabilité de la Fréquence Cardiaque
Données de Variabilité
On s'intéresse à des données comme les variations du rythme cardiaque en fonction du temps ou les variations de la pression artérielle systolique en fonction du temps. Ces données permettent de calculer la variabilité de la fréquence cardiaque ou de la pression artérielle. Il y a typiquement 60 à 100 échantillons par seconde, donc 5 minutes de données occupent un tampon de 300 à 500 échantillons. On émettra des tampons contenant 1024 échantillons. D'autres types de données peuvent être considérés.
Les données en entrée seront sous forme de lignes au format texte CSV (temps, donnée).
Si il y a N canaux, les lignes seront sous la forme:
- (temp1,donnée1,temps2, donnée2,...,tempsN,donnéeN).
La fréquence d'échantillonnage (minimum) après interpolation sera:
- fréquence d'échantillonnage = (nombre total d'échantillons / temps total).
Le nombre (minimum) de trames par seconde sera:
- trames par seconde = (fréquence d'échantillonnage / 1024).
Des fréquences d'échantillonnage très basses ou très élevées ne sont pas des problèmes avec nos codecs.
Les enregistrements seront des fichiers WAVE compressés ou non compressés selon l’option de sauvegarde. Au lieu d'afficher le LTAS ou le HPR, nous allons afficher l'énergie spectrale pour les basses fréquences (LF), l'énergie spectrale pour les hautes fréquences (HF) ainsi que le rapport LF/HF.
Sonification
La sonification concerne les signaux physiologiques et les données de variabilité. Durant les enregistrements ou les lectures, par défaut, il n'y a pas de son pour ces signaux ou ces données, mais des affichages des valeurs des paramètres pour un canal ou pour la moyenne des canaux.
En option, nous allons générer un son par canal (le multicanal sera possible), à l'aide d'un algorithme de sonification de bonne qualité. Nous allons utiliser la sonification par mapping spectral (Spectral Mapping Sonification en Anglais).
La sonification par mapping spectral permet de surveiller toutes les fréquences ou une bande précise de fréquences.
Des études récentes ont montré, par exemple, qu'on pouvait entendre la différence entre un rythme cardiaque normal et un rythme cardiaque anormal grâce à la sonification des signaux de l'ECG.
Plus d'informations sur la sonification des données avec vlrMemos à l'adresse suivante:
- Sonification des Données avec vlrMemos
Envoyer et Partager
Il n'est pas prévu dans l'immédiat d'avoir des fonctions d'envoi et de partage des fichiers créés par vlrMemos. On pourra se servir des applications de messagerie permettant d'envoyer des fichiers (WhatsApp, Skype, ...).
On pourra lire les fichiers WAVE (non compressés ou compressés avec vlrMemos) dans les répertoires accessibles en lecture.
En utilisant vlrMemos en lecture, on pourra utiliser des filtres FIR et HTRF personnalisés. En utilisant les codecs VLC, on pourra utiliser plus efficacement ces filtres, car il n'y aura pas besoin de se placer dans le domaine de Fourier.
Financement Participatif
Nous allons considérer les systèmes d'exploitation suivants:
- Windows.
- Android et Android Wear.
- iOS (iPhone et iPad) et watchOS (Apple Watch).
- Windows Phone.
En option, tous les systèmes supportés par PJSIP pourront être considérés.
La programmation GPU sera faite via les Compute Shaders (disponibles à partir d'OpenGL 4.3 et d'OpenGL ES 3.1).
En option, il y aura le support du SDK MARE (Multicore Asynchronous Runtime Environment en Anglais), dédié au système d'exploitation Android et aux SoCs Qualcomm Snapdragon (GPU Adreno), et du SDK Metal, dédié au système d'exploitation iOS.
Plus d'informations sur le support GPU avec les appareils portables aux adresses suivantes:
- Appareils Portables
- SDK MARE
- SDK Metal
Pour les contreparties, voir sur le site web du financement participatif.
Contrairement à vlrPhone qui est complètement Open Source, vlrMemos va comporter quelques parties propriétaires, principalement l'interface graphique.
PJSIP, tous les codecs VLC et VLR ainsi que d'autres librairies sont Open Source. Les librairies Open Source seront liées statiquement ou dynamiquement aux modules propriétaires. Les codes sources de toutes les librairies Open Source seront publiques.
Utilité
Les paramètres acoustiques calculés et affichés permettront de mesurer la qualité de la voix en vue de:
- détecter des anomalies dans la voix;
- suivre l'efficacité d'un traitement de la voix;
- suivre les progrès réalisés lors d'un entraînement de la voix ou lors d'une rééducation vocale.
On pourra aussi les utiliser à des fins de classification et de recherche.
Nous signalerons en rouge les données en dessous des seuils considérés comme pouvant être pathologiques.
En option, l'application va aussi afficher les courbes de valeurs pour les paramètres acoustiques sélectionnés.
L'application va être compatible avec les sons du corps différents de la voix, dans des situations réelles.
On pourra enregistrer et analyser les sons de battements de coeur et des sons pulmonaires.
L'application sera compatible avec de longs enregistrements.
Nos codecs sont basés sur FFT et stockent directement les valeurs des fréquences, des magnitudes et des phases. En plus de la compression des données, on peut avoir la densité spectrale des signaux lors des lectures, sans refaire de FFT.
La densité spectrale indique la puissance de chaque composante fréquentielle du signal. La densité spectrale peut être utilisée pour analyser directement une variété de signaux physiologiques.
Une modification de la voix est appelée dysphonie, et une voix réduite au chuchotement est appelée aphonie.
Les maladies entraînant des troubles de la voix peuvent être soignées ou retardées plus efficacement si elles sont détectées très tôt.
On peut citer par exemple:
- La laryngite aiguë.
- Le malmenage ou surmenage vocal et les dysphonies dysfonctionnelles.
- Les lésions bénignes des cordes vocales.
- La papillomatose laryngée.
- Les laryngites chroniques.
- La paralysie laryngée.
- Les dysphonies spasmodiques.
- Le cancer des cordes vocales (cancer de la gorge).
- La dysarthrie qui est une faiblesse ou une paralysie des cordes vocales causée par des dommages aux nerfs et/ou au cerveau, par exemple en cas de sclérose en plaques, d'accident vasculaire cérébral ou de maladie de Parkinson.
- L'aphasie qui est due à une perte de la parole ou à des troubles du langage parlé et/ou écrit, par exemple en cas de maladie d'Alzheimer.
Pour certaines professions (comme les conférenciers, les coaches, les enseignants, les animateurs et les chanteurs par exemple), la qualité de la voix est fondamentale.
Pour les fumeurs, la détection d'une anomalie persistante de la voix peut permettre la détection précoce d'une maladie grave comme le cancer du poumon.
L'intérêt de la variabilité de la fréquence cardiaque (VFC) a été démontré dans l'analyse de la récupération des sportifs. La VFC est un excellent indicateur de niveau de santé général et un facteur prédictif de l'hypertension. Un diminution de l'énergie spectrale signale un risque d'évènements cardiaques.
La mesure de la dysphonie permet la détection et le suivi efficace de la maladie de Parkinson.
La maladie d'Alzheimer est caractérisée par:
- Le ralentissement de l'EEG (l'ElectroEncéphalogramme), c'est-à-dire une élévation de la puissance des magnitudes dans les basses fréquences.
- La perte de complexité des signaux de l'EEG.
- La perte de synchronie des signaux de l'EEG.
A partir des signaux issus de l'EEG, les paramètre spectraux ainsi que le coefficient de corrélation croisé multicanal permettent de quantifier ces anomalies.
Des mesures de synchronie plus complexes existent, comme:
- La syncronie de phase.
- Le module Carré de la Cohérence (Magnitude Squared Coherence ou MSC en Anglais).
- La causalité de Granger et les mesures dérivées, notamment la Fonction de Transfert Directe (Direct Transfer Function ou DTF en Anglais). Ces mesures utilisent des zones précises du domaine des fréquences. On pourra utiliser directement les enregistrements dans le domaine des fréquences, surtout dans un contexte de télésurveillance.
Pour terminer, on peut signaler que l'analyse spectrale de puissance des signaux de l'EEG est l'outil le plus utilisé dans la recherche sur le sommeil.
Interfaces de l'Application
Exemples de Résultats
Version = V7 (quasi sans perte en énergie).
LTAS = Spectre Moyenné à Long Terme (Long-Term Average Spectrum en Anglais).
HPR = Rapport de Puissance Hautes Fréquences (High-Frequency Power Ratio en Anglais), avec:
(1)
Plage basses fréquences: 0 - 500 Hz,
Plage hautes fréquences: 500 - 4000 Hz.
(2)
Plage basses fréquences: 0 - 6000 Hz,
Plage hautes fréquences: 6000 - 20000 Hz.
Calculs avec le programme gratuit PRAAT.
Pour le CPPS (Pic de Proéminence Cepstral Lissé ou Smoothed Cepstral Peak Prominence en Anglais), les valeurs par défaut de PRAAT sont utilisées avec la fenêtre moyenne de la quéfrence égale à 0,032 seconde.
|
Voix d'Origine Fréquence d'Echantillonnage de 48 kHz |
Après compression et décompression par le codec VLC HQ 48 à 96000 bps. |
|
Voix d'Homme d'Origine Cliquez Ici pour Ecouter WAV LTAS = 70,064 dB HPR = -6,412 dB (1) HPR = -28,849 dB (2) CPPS: 55,913 dB Quéfrence: 331 Hz |
Voix d'Homme Compressée Cliquez Ici pour Ecouter WAV LTAS = 70,047 dB HPR = -6,402 dB (1) HPR = -29,787 dB (2) CPPS: 57,006 dB Quéfrence: 331 Hz |
|
Voix de Femme d'Origine Cliquez Ici pour Ecouter WAV LTAS = 79,958 dB HPR = -5,428 dB (1) HPR = -27,527 dB (2) CPPS: 55,129 dB Quéfrence: 331 Hz |
Voix de Femme Compressée Cliquez Ici pour Ecouter WAV LTAS = 79,939 dB HPR = -5,432 dB (1) HPR = -28,133 dB (2) CPPS: 55,057 dB Quéfrence: 331 Hz |
Mémos Vocaux.
Mémos Audio, Mémos Sonores.
Mesure de la Qualité de la Voix.
Entraînement de la Voix.
Paramètres Acoustiques.
Spectre Moyenné à Long Terme (Long-Term Average Spectrum ou LTAS en Anglais).
Rapport de Puissance Hautes Fréquences (High-Frequency Power Ratio ou HPR en Anglais).
Jitter.
Shimmer.
Rapport Harmonique sur Bruit (Harmonic to Noise Ratio ou HNR en Anglais).
Pic de Proéminence Cepstral (Cepstral Peak Prominence ou CPP en Anglais).
Pic de Proéminence Cepstral Lissé (Smoothed Cepstral Peak Prominence ou CPPS en Anglais).
Entropie Spectrale.
Point de Rolloff Spectral.
Centroïde Spectral.
Coefficient de Corrélation Croisé Multicanal (Multichannel Cross Correlation Coefficient ou MCCC en Anglais).
Centre de Gravité (Center of Gravity ou COG en Anglais).
Ecart Absolu Moyen, Ecart Type.
Skewness, Kurtosis.
Variabilité de la Fréquence Cardiaque (VFC).
Sons Cardiaques ou Sons de Battements de Coeur.
Sons Pulmonaires ou Sons Respiratoires.
Auto-Quantification (Quantified Self ou Self Training en Anglais).
Sonification par Mapping Spectral (Spectral Mapping Sonification en Anglais).
Audio 3D, Audio Positionnel 3D.
HRTF (Fonction de Transfert Relative à la Tête, Head-Related Transfer Function en Anglais).
Processeur Graphique (GPU, Graphics Processing Unit en Anglais).
|
|
|
|
|
|